


В этом руководстве мы даем обзор моделей Gemini и рассказываем, как эффективно их использовать. Руководство также включает в себя возможности, советы, приложения, ограничения, документы и дополнительные материалы для чтения, связанные с моделями Gemini.
Введение в Gemini
Gemini — это новейшая, наиболее способная модель ИИ от Google Deepmind. Она создана с нуля с учетом мультимодальных возможностей и может демонстрировать впечатляющие кроссмодальные рассуждения в текстах, изображениях, видео, аудио и коде.
Gemini выпускается в трех вариантах:
- Ultra — самая мощная модель серии и подходит для решения очень сложных задач
- Pro — считается лучшей моделью для масштабирования в широком диапазоне задач
- Nano — эффективная модель для задач и сценариев использования с ограниченным объемом памяти на устройстве; включает модели с параметрами 1,8 Б (Nano-1) и 3,25 Б (Nano-2), полученные из больших моделей Gemini и квантованные до 4-бит
Согласно прилагаемому техническому отчету, Gemini превосходит уровень техники в 30 из 32 эталонов, охватывающих такие задачи, как язык, кодирование, рассуждения и мультимодальные рассуждения.
Это первая модель, которая достигла производительности человека-эксперта в MMLU (популярный экзаменационный бенчмарк), и заявляет о своем превосходстве в 20 мультимодальных бенчмарках. Gemini Ultra достигла 90,0 % в MMLU и 62,4 % в MMMU, требующем знания предмета и рассуждений на уровне колледжа.
Модели Gemini обучены поддерживать длину контекста 32k и построены на основе декодеров Transformer с эффективными механизмами внимания (например, многозапросное внимание). Они поддерживают текстовый ввод, чередующийся с аудио- и визуальным вводом, и могут выдавать текст и изображения.
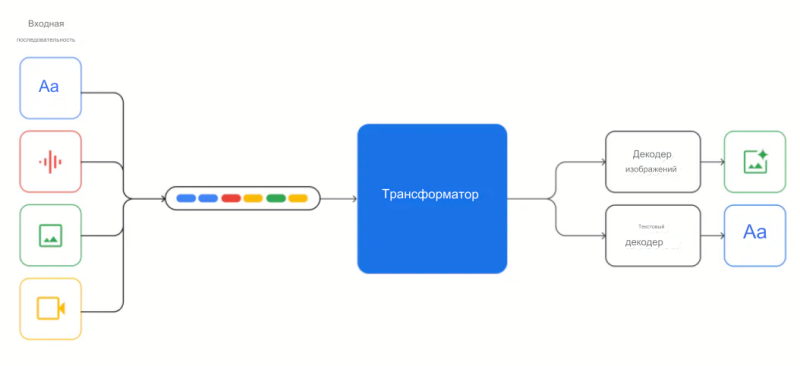
Модели обучаются на мультимодальных и многоязычных данных, таких как веб-документы, книги и кодовые данные, включая изображения, аудио- и видеоданные. Модели обучаются совместно для всех модальностей и демонстрируют сильные кроссмодальные способности к рассуждениям и даже сильные способности в каждой области.
Экспериментальные результаты Gemini
Gemini Ultra достигает наивысшей точности в сочетании с такими подходами, как подсказки по цепочке мыслей (CoT) и самосогласованность, которая помогает справиться с неопределенностью модели.
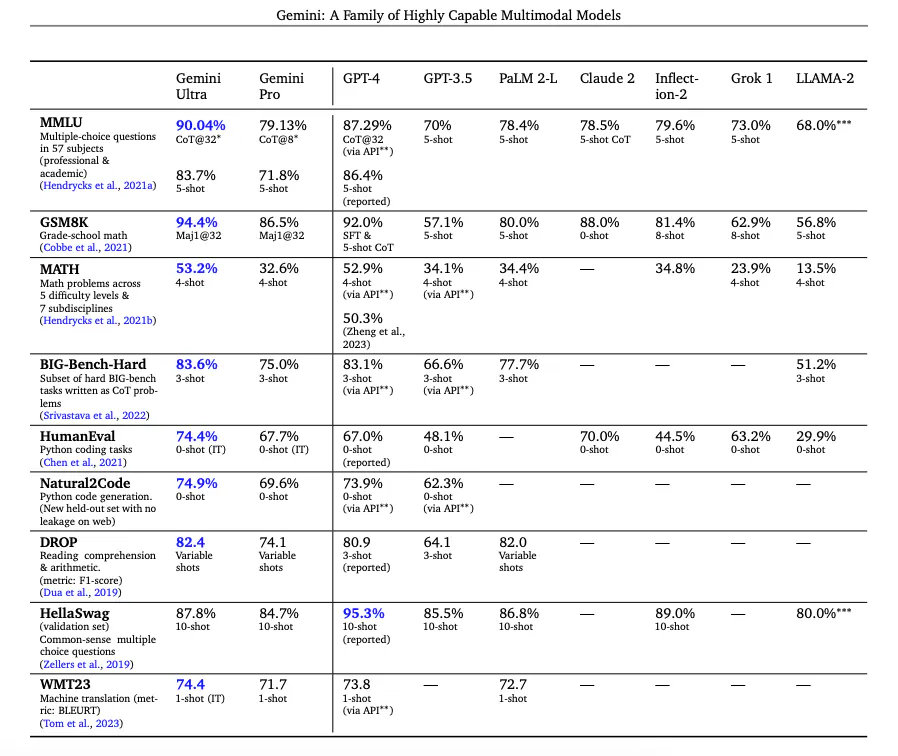
Как сообщается в техническом отчете, Gemini Ultra улучшает свою производительность на MMLU с 84,0% с жадной выборкой до 90,0% с подходом цепочки размышлений, ориентированным на неопределенность (включает CoT и мажоритарное голосование) с 32 выборками, в то время как при использовании только 32 образцов цепочки размышлений она улучшается незначительно до 85,0%. Аналогично, CoT и самосогласованность обеспечивают точность 94,4% в математическом тесте GSM8K для школьников. Кроме того, Gemini Ultra правильно решает 74,4 % задач завершения кода HumanEval. Ниже приведена таблица с результатами Gemini и сравнением моделей с другими известными моделями.
Наномодели Gemini также демонстрируют высокие результаты в задачах на фактологию (т.е. связанных с поиском), рассуждения, STEM, кодирование, мультимодальные и многоязычные задачи.
Помимо стандартных многоязычных возможностей, Gemini демонстрирует отличную производительность в многоязычных математических задачах и задачах обобщения, таких как MGSM и XLSum, соответственно.
Модели Gemini были обучены на последовательности длиной 32K и, как оказалось, могут извлекать правильные значения с точностью 98% при запросах на всю длину контекста. Это важная возможность для поддержки новых сценариев использования, таких как поиск по документам и понимание видео.
Модели Gemini, настроенные на работу с инструкциями, постоянно получают предпочтение от людей, оценивающих такие важные возможности, как следование инструкциям, творческое письмо и безопасность.
Возможности мультимодального рассуждения Gemini
Gemini изначально обучен мультимодальному обучению и демонстрирует способность объединять возможности различных модальностей с возможностями рассуждения языковой модели. Возможности включают, но не ограничиваются извлечением информации из таблиц, графиков и рисунков. Среди других интересных возможностей — выделение мелких деталей из входных данных, агрегирование контекста в пространстве и времени, а также объединение информации из разных модальностей.
Gemini постоянно превосходит существующие подходы в таких задачах понимания изображений, как высокоуровневое распознавание объектов, тонкая транскрипция, понимание графиков и мультимодальные рассуждения. Некоторые из возможностей понимания и создания изображений также переносятся на различные языки мира (например, создание описаний изображений на таких языках, как хинди и румынский).
Обобщение текста — примеры использования промтов
Несмотря на то, что Gemini обучается как мультимодальная система, она обладает многими возможностями, присутствующими в современных больших языковых моделях, таких как GPT-3.5, Claude и Llama. Ниже приведен пример простой задачи обобщения текста с помощью Gemini Pro. Для этого примера мы используем Google AI Studio со значением температуры 0.
Промт:
Ваша задача — кратко изложить суть реферата в одном предложении.
Избегайте технического жаргона и объясните все самыми простыми словами.
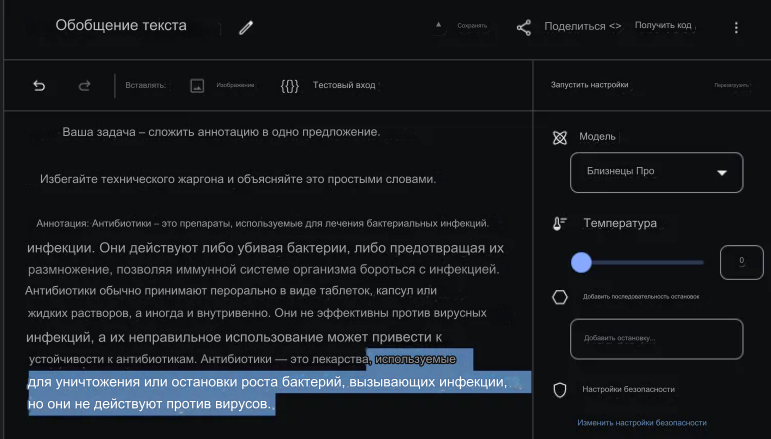
Аннотация: Антибиотики — это тип лекарств, используемых для лечения бактериальных инфекций. Они убивают бактерии или препятствуют их размножению, позволяя иммунной системе организма бороться с инфекцией. Антибиотики обычно принимают перорально в виде таблеток, капсул или жидких растворов, а иногда вводят внутривенно. Они не эффективны против вирусных инфекций, а их неправильное применение может привести к развитию устойчивости к антибиотикам.
Gemini Pro отвечает:
Антибиотики — это лекарства, используемые для уничтожения или остановки роста бактерий, вызывающих инфекции, но они не действуют против вирусов.
Вот скриншот того, как выглядит задача и ответ модели (выделено) в Google AI Studio.
Извлечение информации
Вот еще один пример задачи, которая анализирует фрагмент текста и извлекает нужную информацию. Не забывайте, что здесь используются подсказки с нулевым результатом, поэтому результат не идеальный, но модель работает относительно хорошо.
Промт:
Ваша задача — извлечь названия моделей из аннотаций статей по машинному обучению. Ваш ответ — массив названий моделей в формате [\»имя_модели\»]. Если вы не нашли названия моделей в аннотации или не уверены, верните [\»NA\»].
Аннотация: Большие языковые модели (LLM), такие как ChatGPT и GPT-4, произвели революцию в исследованиях по обработке естественного языка и продемонстрировали потенциал в искусственном общем интеллекте (AGI). Однако дорогостоящее обучение и развертывание LLM создают проблемы для прозрачных и открытых академических исследований. Для решения этих проблем в рамках данного проекта осуществляется открытый доступ к китайским LLaMA и Alpaca…
Gemini Pro отвечает:
[\»LLMs\», \»ChatGPT\», \»GPT-4\», \»Chinese LLaMA\», \»Alpaca\»]
Визуальный ответ на вопрос
Визуальный ответ на вопросы предполагает задавание модели вопросов об изображении, переданном в качестве входного сигнала. Модели Gemini демонстрируют различные возможности мультимодальных рассуждений для понимания изображений: графиков, естественных изображений, мемов и многих других типов изображений.
Google AI Studio позволяет проводить тестирование с различными входными данными, для этого нужно нажать на {{}} Тестовый ввод» выше. Затем вы можете добавить тестируемые подсказки в таблицу ниже.
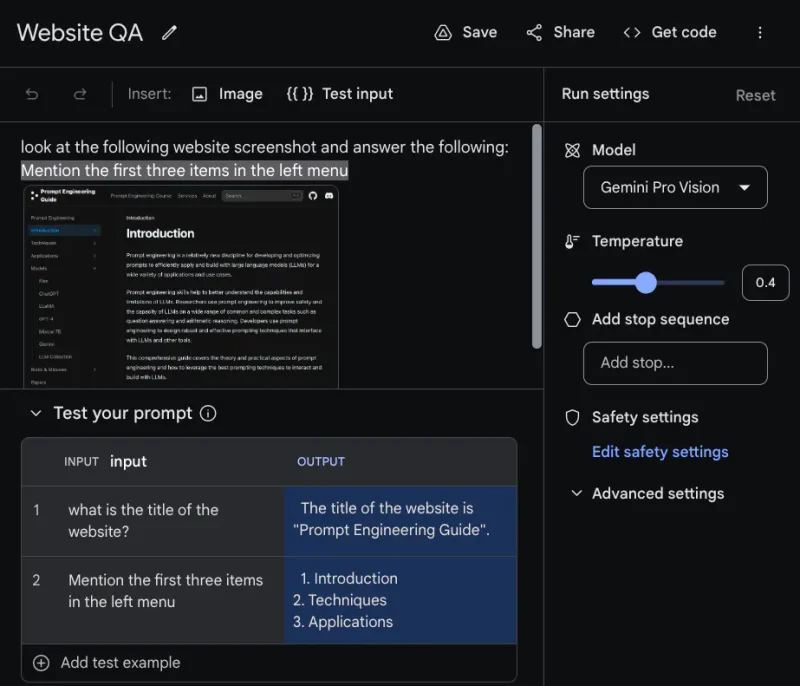
Не стесняйтесь экспериментировать, загружая собственное изображение и задавая вопросы. Сообщается, что Gemini Ultra справляется с подобными задачами гораздо лучше. Мы проведем дополнительные эксперименты, когда модель станет доступной.
Проверка и корректировка
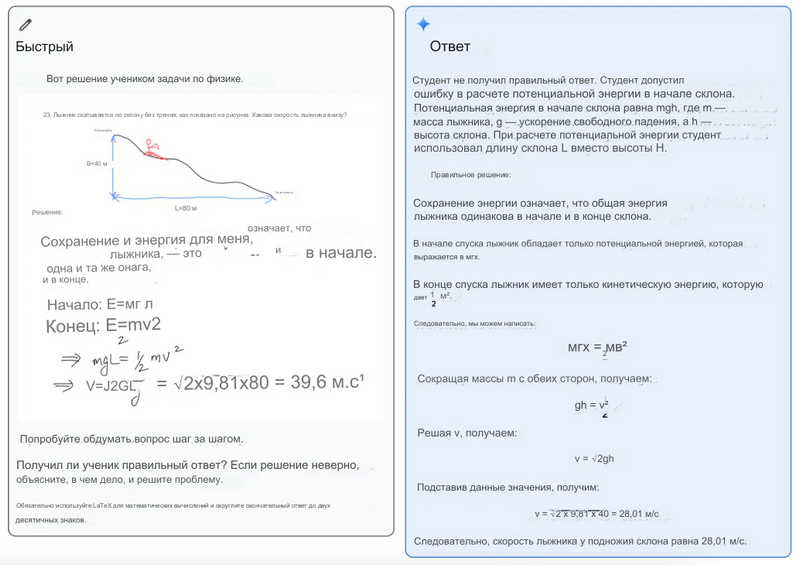
Модели Gemini демонстрируют впечатляющие возможности кроссмодального рассуждения. Например, на рисунке ниже показано решение задачи по физике, нарисованное учителем (слева). Затем Gemini предлагается рассудить вопрос и объяснить, где ученик ошибся в решении, если он это сделал. Модель также получает инструкции по решению задачи и использованию LaTeX для математических частей. Ответ (справа) — это решение, предоставленное моделью, которая подробно объясняет проблему и решение.
Перестановка фигур
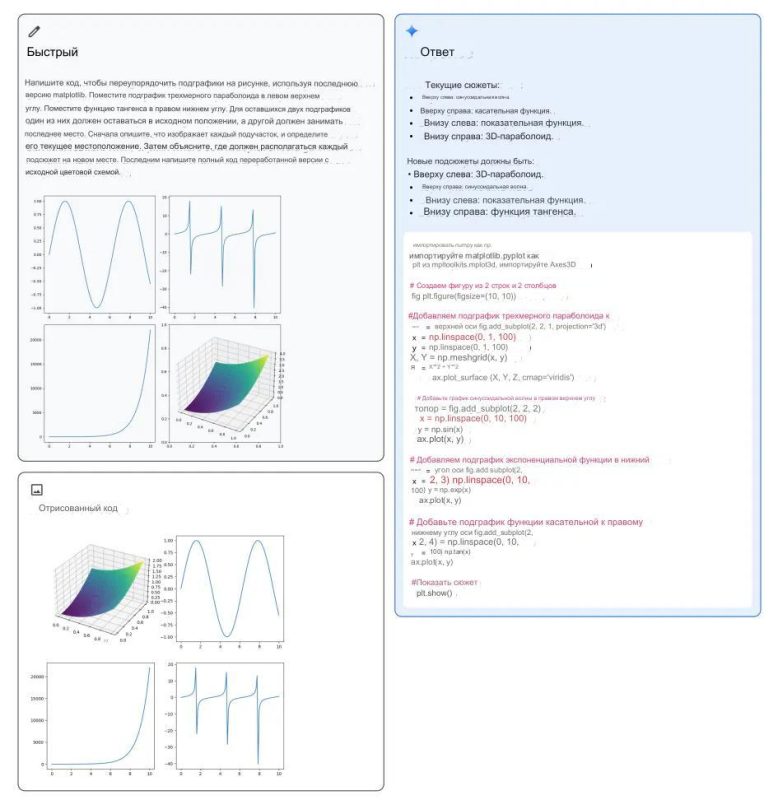
Ниже приведен еще один интересный пример из технического отчета, демонстрирующий возможности мультимодального рассуждения Gemini для генерации кода matplotlib для перестановки подплощадок. Мультимодальная подсказка показана слева вверху, сгенерированный код — справа, а отрисованный код — слева внизу. Модель использует несколько возможностей для решения задачи, таких как распознавание, генерация кода, абстрактное рассуждение о расположении подплат и следование инструкциям для перестановки подплат в нужные позиции.
Понимание видео
Gemini Ultra достигает передовых результатов в различных задачах по созданию подписей к видео и ответам на видеовопросы с нулевыми кадрами. В примере ниже показано, что на вход модели подается видео и текстовая инструкция. Она анализирует видео и рассуждает о ситуации, чтобы дать соответствующий ответ или, в данном случае, рекомендации о том, как человек может улучшить свою технику.

Понимание изображения
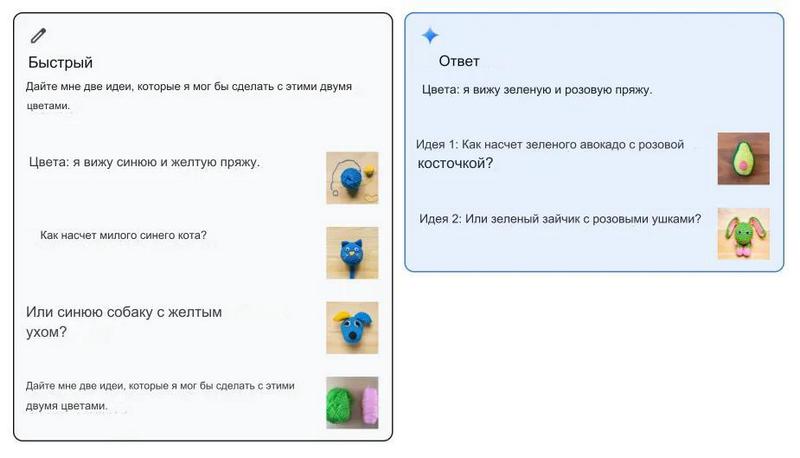
Gemini Ultra также может принимать подсказки в виде нескольких кадров и генерировать изображения. Например, как показано в примере ниже, ей может быть предложен один пример чередования изображения и текста, где пользователь предоставляет информацию о двух цветах и предложениях по изображению. Затем модель воспринимает последнюю инструкцию в подсказке и отвечает на нее, предлагая цвета, которые она видит, а также некоторые идеи.
Комбинирование модальностей
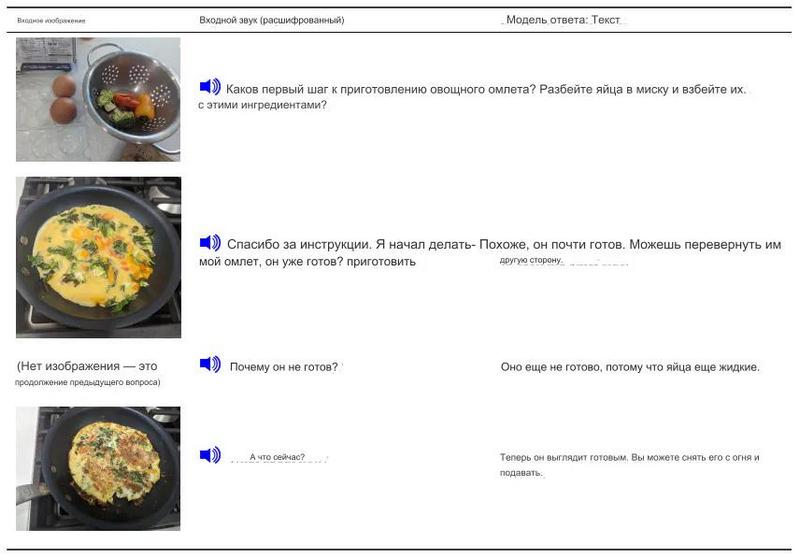
Модели Gemini также демонстрируют способность обрабатывать последовательность аудио и изображений. Из примера видно, что модель может получать подсказки в виде последовательности аудио и изображений. Затем модель способна отправить текстовый ответ, учитывающий контекст каждого взаимодействия.
Агент кодирования общего назначения Gemini
Gemini также используется для создания агента общего назначения под названием AlphaCode 2, который сочетает возможности рассуждения с поиском и использованием инструментов для решения конкурентных задач программирования. AlphaCode 2 входит в 15 % лучших участников на платформе соревновательного программирования Codeforces.
Few-Shot Prompting с Gemini
Few-shot prompting — это подход, который позволяет указать модели, какого рода вывод вы хотите получить. Это полезно для различных сценариев, например, когда вы хотите получить результат в определенном формате (например, объект JSON) или стиле. Google AI Studio также позволяет сделать это в интерфейсе.
Ниже приведен пример использования подсказок в несколько кадров с моделями Gemini.
Мы хотим построить простой классификатор эмоций с помощью Gemini. Первым шагом будет создание «Структурированной подсказки», нажав на «Создать новую» или «+». В подсказке, состоящей из нескольких кадров, будут объединены ваши инструкции (описание задачи) и приведенные вами примеры. На рисунке ниже показана инструкция (вверху) и примеры, которые мы передаем модели. Вы можете настроить текст INPUT и OUTPUT на более описательные показатели. В примере ниже в качестве входных и выходных показателей используются «Text:» и «Emotion:» соответственно.
В целом комбинированная подсказка выглядит следующим образом:
Ваша задача — классифицировать фрагмент текста, разделенный тройными обратными знаками, по следующим меткам эмоций: [«гнев», «страх», «радость», «любовь», «грусть», «удивление»]. Просто выведите метку в виде строки со строчными буквами.
Текст: Я чувствую себя очень злым сегодня
Эмоция: гнев
Текст: Чувствую радость от хороших новостей сегодня.
Эмоция: радость
Текст: Сегодня я действительно чувствую себя хорошо.
Эмоция:
Затем вы можете протестировать подсказку, добавив входные данные в разделе «Test your prompt». Мы используем пример «Я действительно чувствую себя хорошо сегодня.» в качестве входных данных, и модель правильно выводит метку «радость» после нажатия на кнопку «Выполнить». Смотрите пример на рисунке ниже:
Использование библиотеки
Ниже приведен простой пример, демонстрирующий, как вызвать модель Gemini Pro с помощью API Gemini. Вам необходимо установить библиотеку google-generativeai и получить API-ключ от Google AI Studio. В примере ниже приведен код для запуска той же задачи извлечения информации, которая использовалась в разделах выше.
«»»
At the command line, only need to run once to install the package via pip:
$ pip install google-generativeai
«»»
import google.generativeai as genai
genai.configure(api_key=»YOUR_API_KEY»)
# Set up the model
generation_config = {
«temperature»: 0,
«top_p»: 1,
«top_k»: 1,
«max_output_tokens»: 2048,
}
safety_settings = [
{
«category»: «HARM_CATEGORY_HARASSMENT»,
«threshold»: «BLOCK_MEDIUM_AND_ABOVE»
},
{
«category»: «HARM_CATEGORY_HATE_SPEECH»,
«threshold»: «BLOCK_MEDIUM_AND_ABOVE»
},
{
«category»: «HARM_CATEGORY_SEXUALLY_EXPLICIT»,
«threshold»: «BLOCK_MEDIUM_AND_ABOVE»
},
{
«category»: «HARM_CATEGORY_DANGEROUS_CONTENT»,
«threshold»: «BLOCK_MEDIUM_AND_ABOVE»
}
]
model = genai.GenerativeModel(model_name=»gemini-pro»,
generation_config=generation_config,
safety_settings=safety_settings)
prompt_parts = [
«Your task is to extract model names from machine learning paper abstracts. Your response is an array of the model names in the format [\\\»model_name\\\»]. If you don’t find model names in the abstract or you are not sure, return [\\\»NA\\\»]\n\nAbstract: Large Language Models (LLMs), such as ChatGPT and GPT-4, have revolutionized natural language processing research and demonstrated potential in Artificial General Intelligence (AGI). However, the expensive training and deployment of LLMs present challenges to transparent and open academic research. To address these issues, this project open-sources the Chinese LLaMA and Alpaca…»,
]
response = model.generate_content(prompt_parts)
print(response.text)
На выходе получаем то же самое, что и раньше:
[\»LLMs\», \»ChatGPT\», \»GPT-4\», \»Chinese LLaMA\», \»Alpaca\»]







